最弱のHadoopクラスタをRaspberry Piで構築する
はじめに
HadoopのHA勉強したいなーと思い、Hadoopクラスタ組んでみました。
で、環境をどうするかが問題です。
次のパターンでHadoopクラスタ組めないか、考えました。
AWSって最高じゃないですか。でも、手元に物理的な筐体がないと物足りないんですよね。なんだろ、これ。
サーバー自作は最後まで考えました。CPU何にするかまで考えました。でも、物理的に大きなものが、我が家に存在すると、いろいろ問題があるのですよ。奥様的に。で、却下。
インテルのNUC欲しかったです。でもSSDとか電源とか別途購入する必要があり、結果的にコストオーバー。
んで、消去法で、Raspberry PiでHadoopクラスタ組んでみることになりました。
ゴールはNameNode、DataNode、ResourceManager、NodeManagerの起動とします。


構成
NameNode, JobTracker 1台。(node1)
DataNode, TaskTracker 5台。(node2 - node6)
HAなどの構成は未実施。
基本的な設定は疑似分散のときと同様。
/etc/hosts
node1 - node6共通設定
ip6は無効にする
設定変更後はサーバー再起動
#::1 localhost ip6-localhost ip6-loopback #fe00::0 ip6-localnet #ff00::0 ip6-mcastprefix #ff02::1 ip6-allnodes #ff02::2 ip6-allrouters #127.0.1.1 node1 192.168.11.51 node1 192.168.11.52 node2 192.168.11.53 node3 192.168.11.54 node4 192.168.11.55 node5 192.168.11.56 node6
Hadoopインストール
node1 - node6共通設定
/optにhadoopをインストールする
ディレクトリに移動して、解凍して、オーナー変更する
pi@node1 /opt $ sudo tar zxf hadoop-2.5.1.tar.gz pi@node1 /opt/hadoop-2.5.1 $ sudo chown pi -R .
Javaのパス
node1 - node6共通設定
Javaのパスが通っていないと怒られるので、通しておく
/bin/bash: /bin/java: No such file or directory
pi@node1 /opt/hadoop-2.5.1 $ sudo ln -s /usr/bin/java /bin/java
hadoop-env.sh
# export JAVA_HOME=${JAVA_HOME} JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") export HADOOP_HOME=/opt/hadoop-2.5.1 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
core-site.xml
node1 - node6共通設定
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
</configuration>
hdfs-site.xml
node1 - node6共通設定
pi@node1 /opt/hadoop-2.5.1 $ mkdir -p dfs/data pi@node1 /opt/hadoop-2.5.1 $ mkdir -p dfs/name
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.5.1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.5.1/dfs/name</value>
</property>
</configuration>
NameNode初期化
node1のみ
pi@node3 /opt/hadoop-2.5.1 $ bin/hdfs namenode -format pi@node1 /opt/hadoop-2.5.1 $ sbin/hadoop-daemon.sh start namenode pi@node1 /opt/hadoop-2.5.1 $ jps 2917 NameNode 2964 Jps
DataNode起動
node2 - node6
pi@node2 /opt/hadoop-2.5.1 $ sbin/hadoop-daemon.sh start datanode pi@node2 /opt/hadoop-2.5.1 $ jps 2537 Jps 2476 DataNode
http://node1:50070/dfshealth.html#tab-overviewにアクセス

$ time bin/hadoop fs -ls / 14/11/06 12:59:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items drwx------ - pi supergroup 0 2014-09-27 09:27 /tmp drwxr-xr-x - pi supergroup 0 2014-09-27 09:36 /user real 1m1.726s user 0m56.290s sys 0m1.050s
遅いー!
ここまでで、半分終わり
mapred-site.xml
node1 - node6共通設定
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
node1 - node6共通設定
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8082</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8083</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:8084</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:8088</value>
</property>
</configuration>
ResourceManager起動
$ sbin/yarn-daemon.sh start resourcemanager

Apache FlumeとSpark Streaming
はじめに
Flumeから流れてきたデータをSpark Streamingする。
実現したいことのイメージ。

- netcatサーバーでデータ生成
- Flumeはクライアントからデータを受け取り、Sparkに流し込む
- Spark Streamingでデータを集計
環境
- Scala IDE for Ecipse : 2.10.4
- flume-ng-sdk-1.3.1.jar
- spark-assembly-1.1.0-hadoop2.4.0.jar
- spark-streaming-flume_2.10-1.1.0.jar
- spark-streaming-flume-sink_2.10-1.1.0.jar

Spark Streamingを開始する
ソースコードはSparkのサンプルコードをもとに作成。
spark/FlumeEventCount.scala at master · apache/spark · GitHub
package streaming import org.apache.spark.streaming.Milliseconds import org.apache.spark.SparkConf import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.flume.FlumeUtils import org.apache.spark.storage.StorageLevel import org.apache.log4j.Logger import org.apache.log4j.Level object FlumeStreaming { def main(args: Array[String]) { Logger.getLogger("org").setLevel(Level.WARN) val batchInterval = Milliseconds(2000) val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumeEventCount") val ssc = new StreamingContext(sparkConf, batchInterval) val stream = FlumeUtils.createStream(ssc, "localhost", 60000) stream.count().map(cnt => "Received " + cnt + " flume events.").print() ssc.start() ssc.awaitTermination() } }
Flumeを起動する
- ダウンロード&適当な場所で解凍
- 設定ファイル作成
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = localhost a1.sinks.k1.port = 60000 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
- Flume起動
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
telnetで接続し、データを流してみる
$ telnet localhost 44444 Trying ::1... telnet: connect to address ::1: Connection refused Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. data1 OK data1 OK
------------------------------------------- Time: 1414284566000 ms ------------------------------------------- Received 0 flume events. 14/10/26 09:49:26 WARN BlockManager: Block input-0-1414284566000 already exists on this machine; not re-adding it ------------------------------------------- Time: 1414284568000 ms ------------------------------------------- Received 2 flume events. ------------------------------------------- Time: 1414284570000 ms ------------------------------------------- Received 0 flume events.
EcilpseでSpark Streaming
バージョン
Scala IDE for Eclipseはこちらから2.10.4をダウンロード
Download Scala IDE for Eclipse - Scala IDE for Eclipse

Sparkのダウンロードはこちらから1.1.0 for Hadoop 2.4をダウンロード
Downloads | Apache Spark
spark-assembly-1.1.0-hadoop2.4.0.jarを利用する

Spark Streaming Twitterも別途ダウンロード
バージョンはApache Sparkにあわせる(1.1.0)
Maven Repository: org.apache.spark » spark-streaming-twitter_2.10 » 1.1.0
twitter4j 3.0.3はこちらからダウンロード
http://twitter4j.org/archive/
下記サイトに3.0.3を使用せよと指定している
Spark Streaming Programming Guide - Spark 1.1.0 Documentation
Twitter: Spark Streaming’s TwitterUtils uses Twitter4j 3.0.3 to get the public stream of tweets using Twitter’s Streaming API.

Twitter Streaming
package twitter import org.apache.spark.SparkConf import org.apache.spark.streaming.twitter.TwitterUtils import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.Seconds import org.apache.log4j.Logger import org.apache.log4j.Level object TwitterStreaming { def main(args: Array[String]){ Logger.getLogger("org").setLevel(Level.WARN) System.setProperty("twitter4j.oauth.consumerKey", "XXX") System.setProperty("twitter4j.oauth.consumerSecret", "XXX") System.setProperty("twitter4j.oauth.accessToken", "XXX") System.setProperty("twitter4j.oauth.accessTokenSecret", "XXX") val conf = new SparkConf().setMaster("local[2]").setAppName("TwitterStreaming") val ssc = new StreamingContext(conf, Seconds(1)) val tweets = TwitterUtils.createStream(ssc, None) val statuses = tweets.map(status => status.getText()) // statuses.print() val words = statuses.flatMap(status => status.split(" ")) val hashtags = words.filter(word => word.startsWith("#")) val counts = hashtags.countByValueAndWindow(Seconds(60 * 5), Seconds(1)) .map { case(tag, count) => (count, tag) } counts.foreach(rdd => println(rdd.top(10).mkString("\n"))) ssc.checkpoint("checkpoint") ssc.start() ssc.awaitTermination() } }
Spark Streamingのイメージ(超簡易訳)
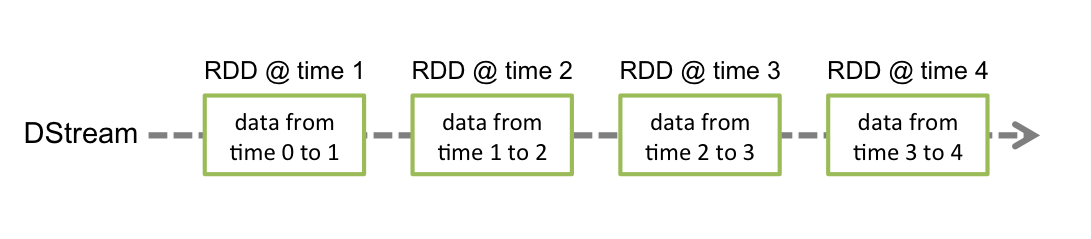
Spark Streamingは高度に抽象化したDStreamと呼ばれる離散的ストーリムを用意している。これでデータの連続したストリームを実現する。

具体的にDStreamは、Spark特有のデータ構造RDDの連続した構造からなる。
Window Operationは、5分間の人気ハッシュタグランキングを計算時など、
一定間隔のストリーミングバッチに利用することができる。
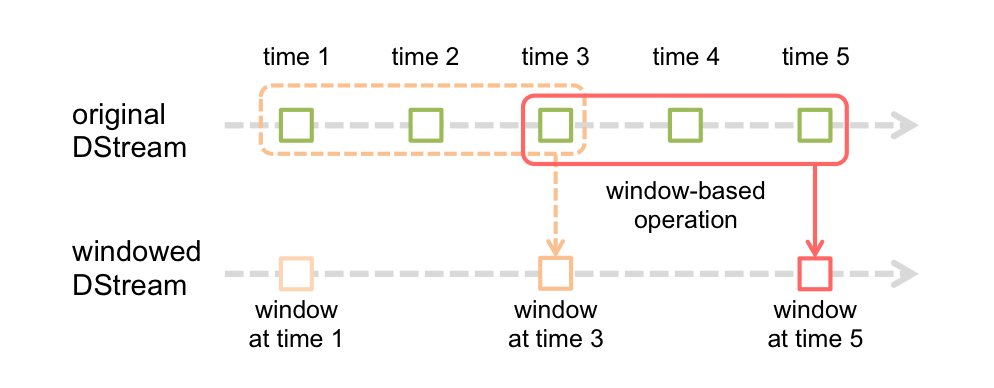
Spark Streaming Programming Guide - Spark 1.1.0 Documentationから画像を引用
Raspberry PiでHadoop(擬似分散モード)を動かす
はじめに
Raspberry PiでHadoopを動かす。
ただし、擬似分散モード。
Raspbianの導入と固定IPの設定まで完了している前提。
Raspberry PiにRaspbianを導入する - もょもとの技術ノート
ゴールはName Node, Data Node, Resource Managerを稼働させ、
円周率を計算するサンプルプログラムを動かすこと。
残念ながら、History Serverも動かすと、サンプルプログラムが原因不明のエラーで失敗してしまう。
一つ一つの動作が超絶遅いので、もー大変だった。
準備
pi@raspberrypi ~ $ sudo apt-get update pi@raspberrypi ~ $ sudo apt-get upgrade
Open JDK導入
pi@raspberrypi ~ $ java -version java version "1.7.0_40" Java(TM) SE Runtime Environment (build 1.7.0_40-b43) Java HotSpot(TM) Client VM (build 24.0-b56, mixed mode)
Oracle Javaをアンインストールせずに、Open JDKを導入。
pi@raspberrypi ~ $ sudo apt-cache search jdk pi@raspberrypi ~ $ sudo apt-get install openjdk-7-jdk pi@raspberrypi ~ $ java -version java version "1.7.0_65" OpenJDK Runtime Environment (IcedTea 2.5.1) (7u65-2.5.1-2~deb7u1+rpi1) OpenJDK Zero VM (build 24.65-b04, mixed mode)
パスフレーズなしでssh ログインできるようにする
pi@raspberrypi ~ $ ssh-keygen -t rsa -P '' pi@raspberrypi ~ $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys pi@raspberrypi ~ $ ssh localhost
解凍
HADOOP_HOMEは/opt/hadoop-2.5.1とした。
pi@raspberrypi /opt $ sudo tar zxf hadoop-2.5.1.tar.gz pi@raspberrypi /opt/hadoop-2.5.1 $ sudo chown pi -R .
hadoop-env.sh
JAVA_HOMEを設定する
pi@raspberrypi /opt/hadoop-2.5.1 $ vi etc/hadoop/hadoop-env.sh
# The java implementation to use.
# export JAVA_HOME=${JAVA_HOME}
JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
core-site.xml
pi@raspberrypi /opt/hadoop-2.5.1 $ vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>あれー、今見直すと、公式ドキュメントは「fs.default.name」ではなくて、「fs.defaultFS」だった。orz
http://hadoop.apache.org/docs/r2.5.1/hadoop-project-dist/hadoop-common/SingleCluster.html
hdfs-site.xml
レプリケーション数を設定する。
擬似分散なので1でよい。
pi@raspberrypi /opt/hadoop-2.5.1 $ vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Secondary Name Node を止める
擬似分散なので(略)
pi@raspberrypi /opt/hadoop-2.5.1 $ vi $ sbin/start-dfs.sh #--------------------------------------------------------- # secondary namenodes (if any) # SECONDARY_NAMENODES=$($HADOOP_PREFIX/bin/hdfs getconf -secondarynamenodes 2>/dev/null) # if [ -n "$SECONDARY_NAMENODES" ]; then # echo "Starting secondary namenodes [$SECONDARY_NAMENODES]" # "$HADOOP_PREFIX/sbin/hadoop-daemons.sh" \ # --config "$HADOOP_CONF_DIR" \ # --hostnames "$SECONDARY_NAMENODES" \ # --script "$bin/hdfs" start secondarynamenode # fi
Name Node初期化
pi@raspberrypi /opt/hadoop-2.5.1 $ ./bin/hadoop namenode -format
Name Node, Data Node起動
pi@raspberrypi /opt/hadoop-2.5.1 $ sbin/start-dfs.sh
ってすると
ssh: Could not resolve hostname with: Name or service not known
というメッセージが大量に出力される。
ssh - Hadoop 2.2.0 : "name or service not known" Warning - Stack Overflow
によるとHadoopのデフォルト ネイティブ ライブラリが32bit用のため、
正しいパスを教えてやらんといけないとのこと。
hadoop-env.shに下記を追記。
pi@raspberrypi /opt/hadoop-2.5.1 $ vi etc/hadoop/hadoop-env.sh export HADOOP_HOME=/opt/hadoop-2.5.1 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
再度、start-dfs.shを実行する。
Name Node, Data Nodeの起動確認
http://192.168.1.X:50070/ にアクセス。
ファイアウォールを設定している場合は、注意が必要。
DataNodeの起動には数分時間を要した。

HDFSにディレクトリを作成してみる
pi@raspberrypi /opt/hadoop-2.5.1 $ bin/hadoop fs -mkdir /user pi@raspberrypi /opt/hadoop-2.5.1 $ bin/hadoop fs -ls /
問題なければ、OK
Resource Managerの起動
pi@raspberrypi /opt/hadoop-2.5.1 $ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
pi@raspberrypi /opt/hadoop-2.5.1 $ vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>pi@raspberrypi /opt/hadoop-2.5.1 $ vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>pi@raspberrypi /opt/hadoop-2.5.1 $ sbin/start-yarn.sh
Resource Managerの起動確認
http://192.168.1.X:8088/ にアクセス。

円周率プログラム起動
pi@raspberrypi /opt/hadoop-2.5.1 $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar pi 1 1
ってやるとまた、エラーが発生。
/binにJavaのパスがないといけないとのこと。
http://cloudcelebrity.wordpress.com/2014/01/31/yarn-job-problem-application-application_-failed-1-times-due-to-am-container-for-xx-exited-with-exitcode-127/
pi@raspberrypi /opt/hadoop-2.5.1 $ sudo ln -s /usr/bin/java /bin/java
これで、うまくいくかなーと思いつつ、再度実行すると
Exception from container-launch: ExitCodeException exitCode=1:
のエラーが多発。ログを見てもなんの情報なく、途方にくれる。
次の日、Name Nodeを初期化して、再度実行すると何故かうまく行った。
うーむ、一番困るパターン。
また、Map Reduceは正常終了するものの、ログに次のメッセージが大量に出る。
Retrying connect to server: 0.0.0.0/0.0.0.0:10020.
hadoop - Connection Error in Apache Pig - Stack Overflowを
参考にするとHistory Serverを起動せねばならないとのこと。
pi@raspberrypi /opt/hadoop-2.5.1 $ sbin/mr-jobhistory-daemon.sh start historyserver
これを起動すると、再接続メッセージはなくなるが、Map Reduceが正常終了しなくなるという
意味不明状態。
まとめ
Name Node, Data Node, Resource Managerを稼働させ、
円周率を計算するサンプルプログラムを動かすことはできた。
History Serverも起動させてMapReduceを正常動作させることはできていない。orz
Raspberry PiにRaspbianを導入する
はじめに
1. DebianベースのRaspberry Pi用OS、Raspbianを導入する
2. HDMIは使用しないで、SSHで設定する
3. 固定IPを設定する

使用したのはRaspberry Pi Model B+
- CPU : 700 MHz
- メモリ : 512MB
- ストレージ : microSD 16GB (別途購入、ハードディスクとか付いてないよ)
電源はMicro USB 1Aの電源も別途購入

ブートmicroSDの作成
Raspbianのダウンロード
ダウンロードしたファイルは「2014-06-20-wheezy-raspbian.img」
ブートSDカードを作成するためのMac用アプリをダウンロード
ダウンロードしたファイルは「RPi-sd card builder v1.2.app」
最初はddコマンドでブートSDカードの作成を試みたが、
半日たってもファイル書き込みが、完了しなかったので、諦めた。
RPi-sd card builderだと、数分で完了。
完了したらmicroSDとLANケーブルをセットして起動。
SSHでアクセス
ルーターにアクセスし、DHCPでRaspbianに割り振られたIPを確認する。
初期ユーザー名 : pi
初期パスワード : raspberry
$ ssh pi@192.168.1.X
初期設定
- microSDカードのブート領域以外も利用できるようにする
最初は2Gポッチしか利用できない
pi@raspberrypi ~ $ df -h Filesystem Size Used Avail Use% Mounted on rootfs 2.6G 2.1G 430M 83% / /dev/root 2.6G 2.1G 430M 83% / devtmpfs 215M 0 215M 0% /dev tmpfs 44M 208K 44M 1% /run tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 88M 0 88M 0% /run/shm /dev/mmcblk0p1 56M 9.5M 47M 17% /boot
- 設定を変更する
pi@raspberrypi ~ $ sudo raspi-config
1. Expand Filesystemを選択する

- 再起動
pi@raspberrypi ~ $ sudo reboot
- 確認
pi@raspberrypi ~ $ df -h Filesystem Size Used Avail Use% Mounted on rootfs 15G 2.1G 12G 15% / /dev/root 15G 2.1G 12G 15% / devtmpfs 215M 0 215M 0% /dev tmpfs 44M 208K 44M 1% /run tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 88M 0 88M 0% /run/shm /dev/mmcblk0p1 56M 9.5M 47M 17% /boot
OK!
パスワード変更
pi@raspberrypi ~ $ passwd
固定IP設定
pi@raspberrypi ~ $ sudo vi /etc/network/interfaces auto lo iface lo inet loopback iface eth0 inet static address 192.168.1.51 network 192.168.1.0 netmask 255.255.255.0 broadcast 192.168.1.255 gateway 192.168.1.1 allow-hotplug wlan0 iface wlan0 inet manual wpa-roam /etc/wpa_supplicant/wpa_supplicant.conf iface default inet dhcp
- 再起動
pi@raspberrypi ~ $ sudo reboot
PassengerでRailsアプリを複数稼働させながら、静的コンテンツも提供する
やりたいこと
- /var/www/html/contentsとかで静的コンテンツを提供する
- /opt/appとかにrailsアプリ作ってPassengerから提供する
Apache管理下にrailsアプリのリンクをはる
sudo ln -s /opt/rails_app1/public /var/www/html/rails_app1 sudo ln -s /opt/rails_app2/public /var/www/html/rails_app2
publicに対してリンクはる!
Apacheの設定ファイル変更
- RailsBaseURIにシンボリックリンク指定
- FollowSymLinksでシンボリックリンクを利用できるようにする
- Productionが稼働するようにSetEnvでSECRET_KEY_BASEを設定
sudo vi /etc/apache2/sites-enabled/000-default.conf
# Passenger LoadModule passenger_module /usr/local/lib/ruby/gems/2.1.0/gems/passenger-4.0.50/buildout/apache2/mod_passenger.so PassengerRoot /usr/local/lib/ruby/gems/2.1.0/gems/passenger-4.0.50 PassengerDefaultRuby /usr/local/bin/ruby <VirtualHost *:80> ServerName www.yourhost.com ServerAdmin webmaster@localhost DocumentRoot /var/www/html # Rails Link Name RailsBaseURI /rails_app1 RailsBaseURI /rails_app2 <Directory /var/www/html> AllowOverride all Options -MultiViews # Symbolic link Options Indexes FollowSymLinks Require all granted # Rails Secret Key for Production SetEnv SECRET_KEY_BASE abcdef </Directory> ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined </VirtualHost>
まとめ
以上で、Webブラウザからrailsアプリにアクセスでき、
/var/www/html下の静的コンテンツにもアクセスできる
プロキシ環境下でElasticsearchにRubyから接続できない
問題
プロキシ環境下で、localhostに立てたElasticsearchに
gem elasticsearchを用いて、Rubyプログラムから接続を試みると、
プロキシサーバーを通して外に接続しに行こうとする orz...
バージョン
- Ruby 2.1.2p95
- Elasticsearch 1.3.2
- elasticsearch(gem) 1.0.4
原因
gem elasticsearchは内部でFaradayを利用している。
そのFaradayは環境変数ENVのhttp_proxyを読み込み、
プロキシ経由のネットワーク接続設定を行っている。
そして、no_proxyの設定を読み取ってくれてない orz...
安易な解決策
require 'elasticsearch' ENV["http_proxy"] = nil #このプログラムではプロキシを無効化 client = Elasticsearch::Client.new p client.info