Apache SparkでカスタムStreamingする
はじめに
Spark, SQL on Hadoop etc. Advent Calendar 2014 - Qiita 3日目の記事です。
SparkでカスタムStreamingする方法を紹介します。
TwitterやFlumeなどのSpark Streamingの活用例が下記にあります。
spark/examples/src/main/scala/org/apache/spark/examples/streaming at master · apache/spark · GitHub
spark/external at master · apache/spark · GitHub
これらは、いろいろ利用できそうですね。
一方で、オリジナルのStreaming処理を行いたい場合には、
Sparkが提供するReceiverクラスを拡張する必要があります。
この記事では、Receiverクラスを拡張して、
カスタムしたStreaming処理を行う方法について紹介します。
ざっくりとしたSparkの説明
Apache Sparkについて秒速で振り返ります
- はやい
インメモリだからHadoopのMapReduceより、はやい
- 使いやすい
Java、Scala、Pythonで書ける
並行処理を実現するための便利APIがたくさんある
- すごい
機会学習、ストリーミング処理、SQLライクな処理、グラフなんでもできる
もうなんかすごい、プラットフォームだこれは
次に、Spark Streamingについて簡単に見ていきます。
ざっくりとしたSpark Streamingの説明
Streaming処理で何ができるのか
ドカドカ流れてくるログデータ等をバッチで一括処理するのとは別に、
より短時間の処理を実現できます。
- 使いやすい
Spark Streamingでは、もちろんSparkのAPIが利用できるので、いろいろ便利です
- 耐障害性
耐障害性がある。今度はこの辺も検証してみたいです
言葉だけだと、イメージがつかめないのでコードを見ていきたいと思います。
Twitter Streaming概要
Twitter Streamingのサンプルコードを見て、Spark Streamingの雰囲気をつかみます。
spark/TwitterPopularTags.scala at master · apache/spark · GitHubから抜粋します
val sparkConf = new SparkConf().setAppName("TwitterPopularTags") val ssc = new StreamingContext(sparkConf, Seconds(2)) val stream = TwitterUtils.createStream(ssc, None, filters) val hashTags = stream.flatMap(status => status.getText.split(" ").filter(_.startsWith("#"))) val topCounts60 = hashTags.map((_, 1)).reduceByKeyAndWindow(_ + _, Seconds(60)) .map{case (topic, count) => (count, topic)} .transform(_.sortByKey(false)) // Print popular hashtags topCounts60.foreachRDD(rdd => { val topList = rdd.take(10) println("\nPopular topics in last 60 seconds (%s total):".format(rdd.count())) topList.foreach{case (count, tag) => println("%s (%s tweets)".format(tag, count))} })
1分間の頻出ハッシュタグを集計するコードです。
ストリーム処理するためのAPI(TwitterUtils.createStream)を起点に、
空白で文字列を分割し、#で始まる単語を抽出し、
1分間あたりの単語数を集計しています。
直感的で分かりやすいですね。
Sparkが事前に用意しているAPIは、
Flume、Kafka、MQTT、Twitter、ZeroMQです。
spark/external at master · apache/spark · GitHub
よって、自分たちの目的にあわせたStreamin処理を行うには、
別の手段が必要になります。
オリジナルStreaming
ここから本題です。
いきなりですが、オリジナルのStreaming処理を行うには、Receiverクラスを拡張します。
ということで、Receiverクラスを見てみます。
spark/Receiver.scala at master · apache/spark · GitHub
仕様がいろいろ書かれてます。
重要なのはonStartメソッドとonStopメソッドです。これらをオーバーライドして、オリジナルのReceiverを作成します。
onStartメソッド
- データを受け取るために、スレッドとかのリソースはここで初期化する
- Spark上で処理できるように、受け取ったデータはstoreメソッドに渡す
- Non Blockingである必要がある
しかし、ここの公式ドキュメントはNon Blockingでないんですよね。
Spark Streaming Custom Receivers - Spark 1.1.1 Documentation
onStopメソッド
- Receiverが終了したときに呼ばれる
- 終了処理を書く
Sparkのサンプルは全体的にonStop処理が軽視されているような気がします。
そういうのって良くないですよね。でもすいません、今回は範囲外とさせてください。
今回やりたいこと

telnetなどのクライアントでSpark Streamingに接続し、
送信したテキストの出現回数を集計したいと思います。
Non BlockingはNettyで実現します。むしろNettyをやりたかった。
登場人物
- PrintReceiver : ネットワーク経由でテキストを受け取る。Non BlockingはNettyで実現する
- PrintUtils : Receiverのためのインターフェース的な役割です
- TestPrintStreaming : 実行クラス
PrintReceiver
import org.apache.spark.streaming._ import org.apache.spark.streaming.dstream._ import org.apache.spark.storage._ import org.apache.spark.Logging import org.apache.spark.streaming.receiver.Receiver import java.net.ServerSocket import java.io.BufferedReader import java.io.InputStreamReader import io.netty.bootstrap.ServerBootstrap import io.netty.buffer.ByteBuf import io.netty.channel._ import io.netty.channel.nio.NioEventLoopGroup import io.netty.channel.socket.SocketChannel import io.netty.channel.socket.nio.NioServerSocketChannel import io.netty.handler.logging._ class PrintInputDStream(@transient ssc_ : StreamingContext, storageLevel: StorageLevel) extends ReceiverInputDStream[String](ssc_) { override def getReceiver(): Receiver[String] = { new PrintReceiver(storageLevel) } } class PrintReceiver(storageLevel: StorageLevel) extends Receiver[String](storageLevel) with Logging { def onStart() { // メインはNettyコード val bossGroup = new NioEventLoopGroup(1); val workerGroup = new NioEventLoopGroup(); try { val bootstrap = new ServerBootstrap(); bootstrap.group(bossGroup, workerGroup) .channel(classOf[NioServerSocketChannel]) .handler(new LoggingHandler(LogLevel.INFO)) .childHandler(new ChannelInitializer[SocketChannel] { override def initChannel(socketChannel: SocketChannel) { val pipeline = socketChannel.pipeline pipeline.addLast(new ChannelHandlerAdapter { override def channelRead(ctx: ChannelHandlerContext, msg: Object) { val buf = msg.asInstanceOf[ByteBuf] val str = new StringBuilder while (buf.isReadable) { // 文字を文字列にする str.append(buf.readByte.asInstanceOf[Char]); } store(str.toString.trim) // 受け取った文字列をSparkに渡す } }) } }) val f = bootstrap.bind(60000).sync(); // ポート番号 f.channel().closeFuture().sync(); } finally { bossGroup.shutdownGracefully(); workerGroup.shutdownGracefully(); } } def onStop() { } }
PrintUtils
import java.net.InetSocketAddress import org.apache.spark.annotation.Experimental import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.api.java.{JavaReceiverInputDStream, JavaStreamingContext} import org.apache.spark.streaming.dstream.ReceiverInputDStream object PrintUtils { def createStream (ssc: StreamingContext, storageLevel: StorageLevel ): ReceiverInputDStream[String] = { new PrintInputDStream(ssc, storageLevel) } }
TestPrintStreaming
import org.apache.spark.SparkConf import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.Seconds import org.apache.spark.storage.StorageLevel import org.apache.log4j.Logger import org.apache.log4j.Level import main.scala.spark.streaming.print.PrintUtils object TestPrintStreaming { def main(args: Array[String]) { Logger.getLogger("org").setLevel(Level.WARN) val conf = new SparkConf().setMaster("local[2]").setAppName("PrintStreaming") val ssc = new StreamingContext(conf, Seconds(1)) val nc = PrintUtils.createStream(ssc, StorageLevel.MEMORY_AND_DISK_SER_2) val counts = nc.countByValueAndWindow(Seconds(60 * 1), Seconds(1)) counts.print ssc.checkpoint("checkpoint") ssc.start() } }
実行結果
------------------------------------------- Time: 1417525094000 ms ------------------------------------------- (hello,6) (hellohellohello,3) (hellohellohellohellohellohello,1) ------------------------------------------- Time: 1417525095000 ms ------------------------------------------- (hello,6) (hellohellohello,3) (hellohellohellohellohellohello,1) ------------------------------------------- Time: 1417525096000 ms ------------------------------------------- (hello,6) (hellohellohello,3) (hellohellohellohellohellohello,1) 14/12/02 21:58:16 WARN storage.BlockManager: Block input-0-1417525096000 already exists on this machine; not re-adding it
まとめ
とまあ、こんな感じでカスタムStreamingしてみました。
いろいろ世界が広がりそうで、楽しいです。
簡単にNon Blockingを実現するためにNettyを用いましたが、
Nettyの調査に一番時間を要しちゃいました。
あと、ActorReceiverなんてものあります。
spark/ActorReceiver.scala at master · apache/spark · GitHub
Apache FlumeとSpark Streaming
はじめに
Flumeから流れてきたデータをSpark Streamingする。
実現したいことのイメージ。

- netcatサーバーでデータ生成
- Flumeはクライアントからデータを受け取り、Sparkに流し込む
- Spark Streamingでデータを集計
環境
- Scala IDE for Ecipse : 2.10.4
- flume-ng-sdk-1.3.1.jar
- spark-assembly-1.1.0-hadoop2.4.0.jar
- spark-streaming-flume_2.10-1.1.0.jar
- spark-streaming-flume-sink_2.10-1.1.0.jar

Spark Streamingを開始する
ソースコードはSparkのサンプルコードをもとに作成。
spark/FlumeEventCount.scala at master · apache/spark · GitHub
package streaming import org.apache.spark.streaming.Milliseconds import org.apache.spark.SparkConf import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.flume.FlumeUtils import org.apache.spark.storage.StorageLevel import org.apache.log4j.Logger import org.apache.log4j.Level object FlumeStreaming { def main(args: Array[String]) { Logger.getLogger("org").setLevel(Level.WARN) val batchInterval = Milliseconds(2000) val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumeEventCount") val ssc = new StreamingContext(sparkConf, batchInterval) val stream = FlumeUtils.createStream(ssc, "localhost", 60000) stream.count().map(cnt => "Received " + cnt + " flume events.").print() ssc.start() ssc.awaitTermination() } }
Flumeを起動する
- ダウンロード&適当な場所で解凍
- 設定ファイル作成
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = localhost a1.sinks.k1.port = 60000 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
- Flume起動
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
telnetで接続し、データを流してみる
$ telnet localhost 44444 Trying ::1... telnet: connect to address ::1: Connection refused Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. data1 OK data1 OK
------------------------------------------- Time: 1414284566000 ms ------------------------------------------- Received 0 flume events. 14/10/26 09:49:26 WARN BlockManager: Block input-0-1414284566000 already exists on this machine; not re-adding it ------------------------------------------- Time: 1414284568000 ms ------------------------------------------- Received 2 flume events. ------------------------------------------- Time: 1414284570000 ms ------------------------------------------- Received 0 flume events.
EcilpseでSpark Streaming
バージョン
Scala IDE for Eclipseはこちらから2.10.4をダウンロード
Download Scala IDE for Eclipse - Scala IDE for Eclipse

Sparkのダウンロードはこちらから1.1.0 for Hadoop 2.4をダウンロード
Downloads | Apache Spark
spark-assembly-1.1.0-hadoop2.4.0.jarを利用する

Spark Streaming Twitterも別途ダウンロード
バージョンはApache Sparkにあわせる(1.1.0)
Maven Repository: org.apache.spark » spark-streaming-twitter_2.10 » 1.1.0
twitter4j 3.0.3はこちらからダウンロード
http://twitter4j.org/archive/
下記サイトに3.0.3を使用せよと指定している
Spark Streaming Programming Guide - Spark 1.1.0 Documentation
Twitter: Spark Streaming’s TwitterUtils uses Twitter4j 3.0.3 to get the public stream of tweets using Twitter’s Streaming API.

Twitter Streaming
package twitter import org.apache.spark.SparkConf import org.apache.spark.streaming.twitter.TwitterUtils import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.Seconds import org.apache.log4j.Logger import org.apache.log4j.Level object TwitterStreaming { def main(args: Array[String]){ Logger.getLogger("org").setLevel(Level.WARN) System.setProperty("twitter4j.oauth.consumerKey", "XXX") System.setProperty("twitter4j.oauth.consumerSecret", "XXX") System.setProperty("twitter4j.oauth.accessToken", "XXX") System.setProperty("twitter4j.oauth.accessTokenSecret", "XXX") val conf = new SparkConf().setMaster("local[2]").setAppName("TwitterStreaming") val ssc = new StreamingContext(conf, Seconds(1)) val tweets = TwitterUtils.createStream(ssc, None) val statuses = tweets.map(status => status.getText()) // statuses.print() val words = statuses.flatMap(status => status.split(" ")) val hashtags = words.filter(word => word.startsWith("#")) val counts = hashtags.countByValueAndWindow(Seconds(60 * 5), Seconds(1)) .map { case(tag, count) => (count, tag) } counts.foreach(rdd => println(rdd.top(10).mkString("\n"))) ssc.checkpoint("checkpoint") ssc.start() ssc.awaitTermination() } }
Spark Streamingのイメージ(超簡易訳)
Spark Streamingは高度に抽象化したDStreamと呼ばれる離散的ストーリムを用意している。これでデータの連続したストリームを実現する。

具体的にDStreamは、Spark特有のデータ構造RDDの連続した構造からなる。
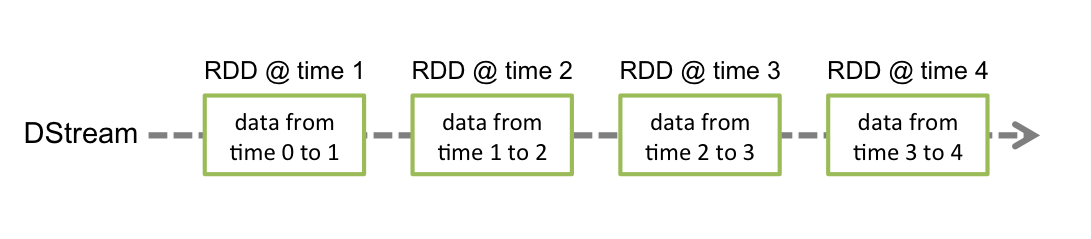
Window Operationは、5分間の人気ハッシュタグランキングを計算時など、
一定間隔のストリーミングバッチに利用することができる。
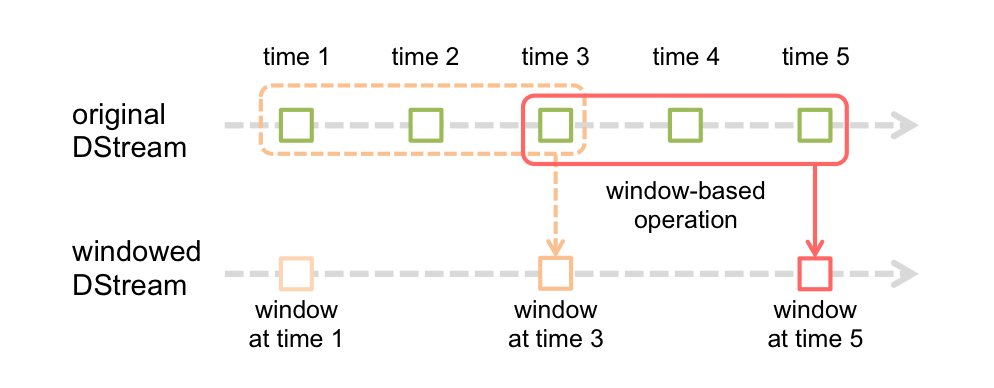
Spark Streaming Programming Guide - Spark 1.1.0 Documentationから画像を引用
Apache SparkでTwitter Streaming
はじめに
Apache Sparkを利用してTwitter Streamingを取得する。
題材はampcampのHands-on Exercisesを活用する。
Hands-on Exercisesはシリーズ物でEC2で稼働させたり、クラスタやHDFSが必要みたいだけど、それらなしでがんばる。
前提条件
必要なもの
- Sparkのインストール
- Scala
- ダウンロードして適当なディレクトリで解凍、パスを通す
- TwitterのConsumer key (API key), Consumer secret (API secret), Access token, Access token secret
- ここで取得できますよ
- amplab/trainingが提供しているソースコード
- ダウンロードして適当なディレクトリで解凍する、以降ここが作業ディレクトリ
- Javaのバージョンは1.8.0_05だとうまく動かないので1.7.0_60へダウングレード
不必要なもの
export JAVA_HOME=`/System/Library/Frameworks/JavaVM.framework/Versions/A/Commands/java_home -v "1.7"`
export SCALA_HOME=/usr/local/bin/scala-2.11.1
export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin/:$PATH
ソースコード
- build.sbt
name := "Tutorial" scalaVersion := "2.10.0" libraryDependencies ++= Seq( "org.apache.spark" %% "spark-streaming" % "0.9.0-incubating", "org.apache.spark" %% "spark-streaming-twitter" % "0.9.0-incubating" )
提供ファイルのScala Versionは2.10。
それを2.10.0に変更する。
- Tutorial.scala
import org.apache.spark._ import org.apache.spark.SparkContext._ import org.apache.spark.streaming._ import org.apache.spark.streaming.twitter._ import org.apache.spark.streaming.StreamingContext._ import TutorialHelper._ object Tutorial { def main(args: Array[String]) { // Location of the Spark directory val sparkHome = "インストールしたSparkディレクトリを指定" // URL of the Spark cluster val sparkUrl = "local" // Location of the required JAR files val jarFile = "target/scala-2.10/tutorial_2.10-0.1-SNAPSHOT.jar" // HDFS directory for checkpointing // ローカルディレクトリに変更する val checkpointDir = "./hdfs/checkpoint/" // Configure Twitter credentials using twitter.txt TutorialHelper.configureTwitterCredentials() val ssc = new StreamingContext(sparkUrl, "Tutorial", Seconds(1), sparkHome, Seq(jarFile)) val tweets = TwitterUtils.createStream(ssc, None) val statuses = tweets.map(status => status.getText()) statuses.print() ssc.checkpoint(checkpointDir) ssc.start() } }
- twitter.txt
Twitter情報を埋める
consumerKey = consumerSecret = accessToken = accessTokenSecret =
実行
$ sbt/sbt package run
まとめ
とりあえずOK
Apache Sparkをとりあえず動かしてみる
はじめに
Apache Spark 1.0.0 をとりあえず動かしてみる。
スタンドアローン環境でHello World! 的なSparkの初めの一歩を実行する。
前提条件
Javaがインストールされていること。
$ java -version java version "1.8.0_05" Java(TM) SE Runtime Environment (build 1.8.0_05-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.5-b02, mixed mode)
ダウンロード
解凍
$ tar zxvf spark-1.0.0.tgz $ cd spark-1.0.0
動作確認
Sparkを対話モードで起動する。
$ ./bin/spark-shell
無事に起動したら、READMEファイルを読み取って色々操作してみる。
scala> val textFile = sc.textFile("README.md") //ファイル読み取り
textFile: org.apache.spark.rdd.RDD[String] = MappedRDD[1] at textFile at <console>:12
scala> textFile.count() //ファイルの行数を数える
res0: Long = 127
scala> textFile.first() //ファイルの最初の行
res1: String = # Apache Spark
まとめ
Apache SparkのHello World! 的なことは簡単にできた!